











关于 Huemint
TLDR Huemint 使用机器学习为图形设计生成颜色。 它可以根据每种颜色在最终设计中的使用方式生成颜色,而不是生成一个平面调色板并让您弄清楚如何应用它。
使用 Huemint
网上有很多颜色生成工具,但大多数生成的都是 5 种颜色的平面调色板。 这是一个很好的起点,但正确应用这些颜色仍然需要经验和直觉。
Huemint 是一种机器学习系统,用于根据上下文生成颜色,可用于最终设计。 它知道哪些颜色是背景,哪些是前景,哪些是重点。 首先,选择一个设计模板,然后单击页面右上角的(生成)按钮。
如果您找到想要保留的颜色,请单击圆形样本以将其锁定。 当您再次单击(生成)时,下一个结果将考虑您锁定的颜色。
如果您想看到更多样和有创意的结果,请尝试进入设置并增加“创意”滑块(也称为采样温度)。 或者,通过将创造力滑块减小到零来查看统计上最可能的单一颜色。
用于色彩设计的机器学习
在为网站、应用程序或其他图形设计选择颜色时,您的选择通常会受到功利因素的限制。

以这个具有 4 种不同颜色的简单布局为例:文本、徽标、导航栏和背景——我们可能希望主要文本和背景之间具有高对比度,背景和导航栏之间具有低对比度,而徽标和导航栏之间再次具有高对比度。
当设计师为这种布局制作调色板时,理想情况下它应该美观,同时满足所有 4 种颜色所需的对比关系。
为了将这些要求提供给 ML 模型,我们可以将对比关系放在一个表格中,如下所示:

该结构将对比度要求编码为加权图。 它只是说节点 1-2 之间的对比度应该低,1-3/2-4 应该高。
在此矩阵中,每个对比度值均使用 CIE Delta-E 定义,其中 100 = 最大对比度,1 = 最小对比度,0 = 未连接。 (这里我们还定义了一个规范的节点顺序,从背景到前景)
使用这个定义,我们可以提取现有设计的对比关系。 例如,这是蒙德里安画作的色彩对比图:


一个简单的渐变:


我们的 ML 系统的总体目标是将颜色对比图作为输入并生成调色板作为输出。
几何直觉
为了直观地了解对比度矩阵的含义,我们可以在 3D 空间(Lab 或 RGB,随您选择)中想象解决方案。 以这个简单的对比图为例:

这意味着我们有 2 种颜色,它们之间的欧几里德距离(在颜色空间中)是 50。如果您在脑海中将这两种颜色想象成 3D 空间中的点,它会形成一条线段。 这条线段的任何旋转或平移都会产生 2 种新颜色,它们之间的距离相同。

如果我们将这个想法扩展到 3 种颜色,那么这 3 个点之间的关系现在就形成了一个等边三角形。 和以前一样,您可以任意平移和旋转这个三角形来创建新的颜色组合。 只要三角形的顶点不越界,它们的对比关系就会保持不变。
我们也可以上下缩放三角形(比如,100 而不是 50)但是在某个点三角形会太大而无法放入 RGB/Lab 立方体中,在这种情况下矩阵被过度约束并且没有解决方案 -换句话说,只有纯黑色和纯白色两种颜色之间的对比度为 100,因此不可能有第三种颜色也可以与这两种颜色形成 100 的对比度。
对于 4 种颜色,形状变为正四面体。 该示例在 n=5 或更多时分解,因为不再有具有等距点的正多面体(因此 5 种颜色的所有 50 的矩阵将没有解决方案)
此时您可能会问,如果我们可以像这样列举所有可能的解决方案,为什么不直接根据第一原理生成颜色——为什么甚至需要机器学习? 答案基本上是色彩空间中的平移和旋转可能是对比度不变的,但它们不是*偏好*不变的。 人类对某些颜色组合的主观偏好优于其他颜色组合,因此要生成令人愉悦的颜色组合,我们需要量化人们通常更喜欢配置空间中的哪些区域。
如果您不相信这一点,请尝试这个实验:使用您最喜欢的图形设计并在 photoshop 中随机旋转其色调。 通常生成的颜色看起来不会很好,即使对比度关系至少应该是相似的。
设计师色彩分布
为了量化图形设计师喜欢哪种颜色组合,我从网上抓取设计缩略图开始。
图形设计往往包含渐变、照片和其他视觉效果,但这些元素可能会引入设计师未特别选择的随机颜色,从而混淆我们的模型。 为了隔离有意的颜色决定,下一步是过滤掉带有照片和渐变的样本,以便仅保留包含平坦颜色区域的设计。
过滤后我得到了 120 万张图片。 这是在 CIE-lab 空间中绘制的样本子集的可视化:
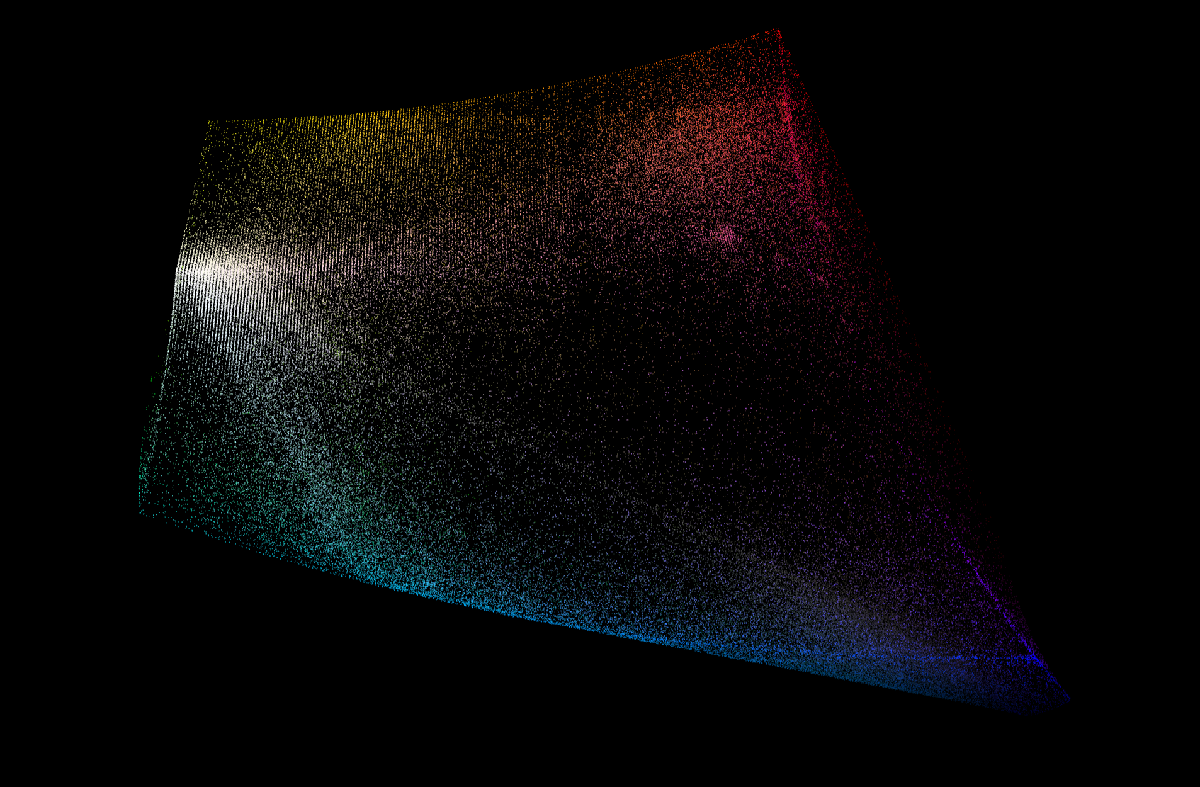
在此可视化中,每个点都是使用颜色的实例。 您可以看到嵌入 Lab 空间的 RGB 立方体,以及略微内嵌的 CMYK 边界。
一些一般性观察:
- 90-95% 的设计包含近白或近黑,具体取决于阈值
- 设计师非常喜欢颜色立方体的边缘(饱和色)
- 在颜色立方体的角落,蓝色和红色很受欢迎,绿色和黄色不太受欢迎,洋红色非常稀疏
主要的收获是设计师倾向于使用的颜色分布非常不均匀。 只需从这个设计师分布中抽样,我们就可以获得看起来“设计感”的颜色(偏向于设计师通常选择的颜色)
开玩笑,你也可以通过故意对低概率区域进行采样来做相反的事情。 我单独演示了它的样子: Poolors
生成模型
在这一点上,我们有一个合适大小的数据集来训练我们的 ML 模型。 总体方法是将问题视为条件图像生成——颜色对比图是输入,相应的调色板是输出。
调色板本质上是一个微小的一维图像,这意味着我们可以使用生成图像领域中的几乎任何模型。 我最终实现了三种不同的算法,主要是因为看到每种方法之间的差异很有趣。
随机的
作为基准,我实现了一个非 ML 算法。 这种模式的工作原理是完全随机地创建调色板,从设计师分布中采样每种颜色。 返回这些随机调色板中最接近所需对比度的前 1%。
为了测试这个系统在多大程度上符合给定的对比度要求,我们可以要求它生成一个渐变调色板。 渐变确保模型所犯的错误在视觉上是显而易见的。



这个系统偶尔能出点好东西,但是命中率很低。 它也有利于在传统设计正统之外获得一些新鲜的想法。
变压器
Transformers 在 NLP 中得到了广泛的应用,但最近才在图像生成领域大放异彩。 为了在图像域中使用它,我们从 OpenAI 的图像 GPT 中获取一个页面并将每个像素量化为一个离散的标记——具体来说,我们使用一个 4096 标记代码本,通过将 K-means 聚类应用于设计师颜色分布来量化。
输入对比图被量化并编码为一组单独的标记,然后作为输入提供给变换器(我们使用编码器-解码器变换器而不是仅解码器)这实际上有点奇怪但是它第一次尝试就起作用了所以我没有不要为更复杂的配方而烦恼。
因为像素标记是以自动回归的方式一次生成一个,所以我们在运行时有更多的旋钮可以调整。 经过一些实验后,我最终使用阈值为 0.8(采样概率质量的 80%)和温度为 1.2 的 top-p 采样
在 NLP 领域,这个值会非常高,但在我们的例子中,我们故意尝试采样更多样化的结果,因此对“关闭”值有更大的容忍度。
以下是不同温度下的几代产品,使用相同的梯度对比矩阵作为输入:






低温值导致仅返回高概率调色板,而高温允许更多多样性但可能不符合我们的对比度要求。
如果我们锁定一种颜色并在 temperature=0 时生成,则只会返回最可能的结果。 对于双色设计,最常见的几代是黑色/白色。


我们还可以尝试为其提供约束不足和过度约束的值(全 0 和全 100 的矩阵),看看它是如何破坏的。 在这种情况下,模型几乎只是忽略了一些对比度值。 考虑到这种类型的数据不在训练集中,它处理得非常好。


扩散模型
DDPM 或 Denoising Diffusion Probabilistic Models 是一类新的生成模型,其灵感来自物理学中的思想。 在 OpenAI 发布了改进的 DDPM 模型的代码后,我立即想到将其应用于颜色生成。
DDPM 的最大问题之一是生成时间长(比 GAN 慢大约 2 个数量级),GPU 无法加速,因为该过程本质上是串行的。
对我们来说幸运的是,我们试图生成的图像非常微不足道(总共 12 个像素),这使得这不是一个问题。
尽管我们的输入数据名义上是一个图形,但该图形又是极其微不足道的。 大多数平面设计具有少于 12 种不同的颜色,其邻接矩阵可以用少于 72 个值表示。 这意味着我们可以将邻接矩阵视为嵌入并将其直接注入模型中。
由于 OpenAI 的代码已经包含类别嵌入,我们可以轻松地将其换成线性层,将邻接嵌入投影到时间嵌入空间中。
以下是 DDPM 模型的一些样本生成,同样具有相同的梯度输入。

生成模型通常使用 FID score 进行评估,但 FID 基于 imagenet,我们的数据与摄影无关,因此很难客观地评估模型。
要查看三种方法之间的差异,我们可以将生成的调色板视为高维向量,并使用 UMAP 在二维中可视化调色板。

红色 = 随机,蓝色 = 变形,绿色 = 扩散
接下来我想看看结果是否符合给定的对比度要求。 我为每种方法生成了一千个调色板,然后绘制输入对比度与每个生成的调色板对比度之间的平均差异。
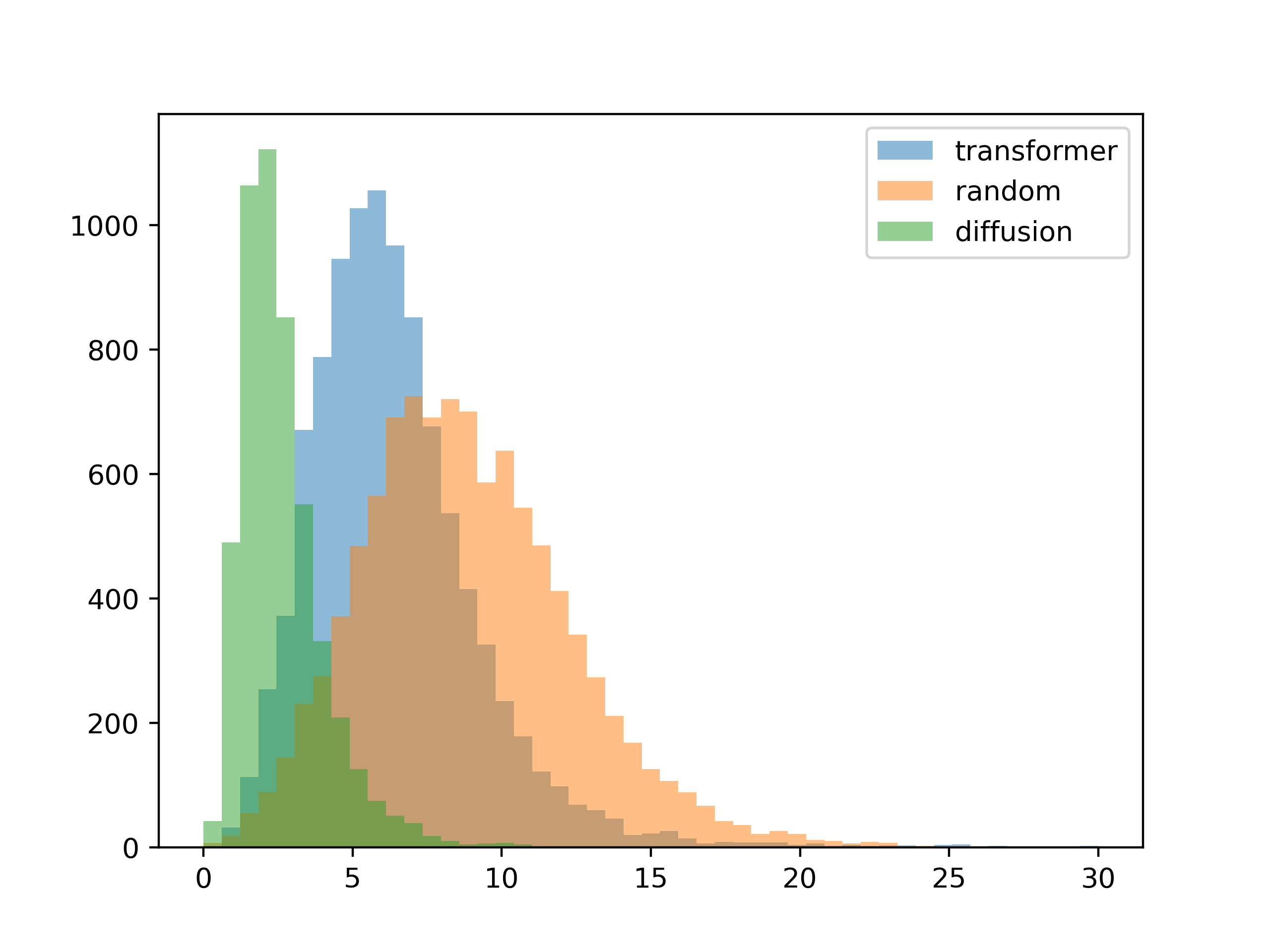 5种颜色
5种颜色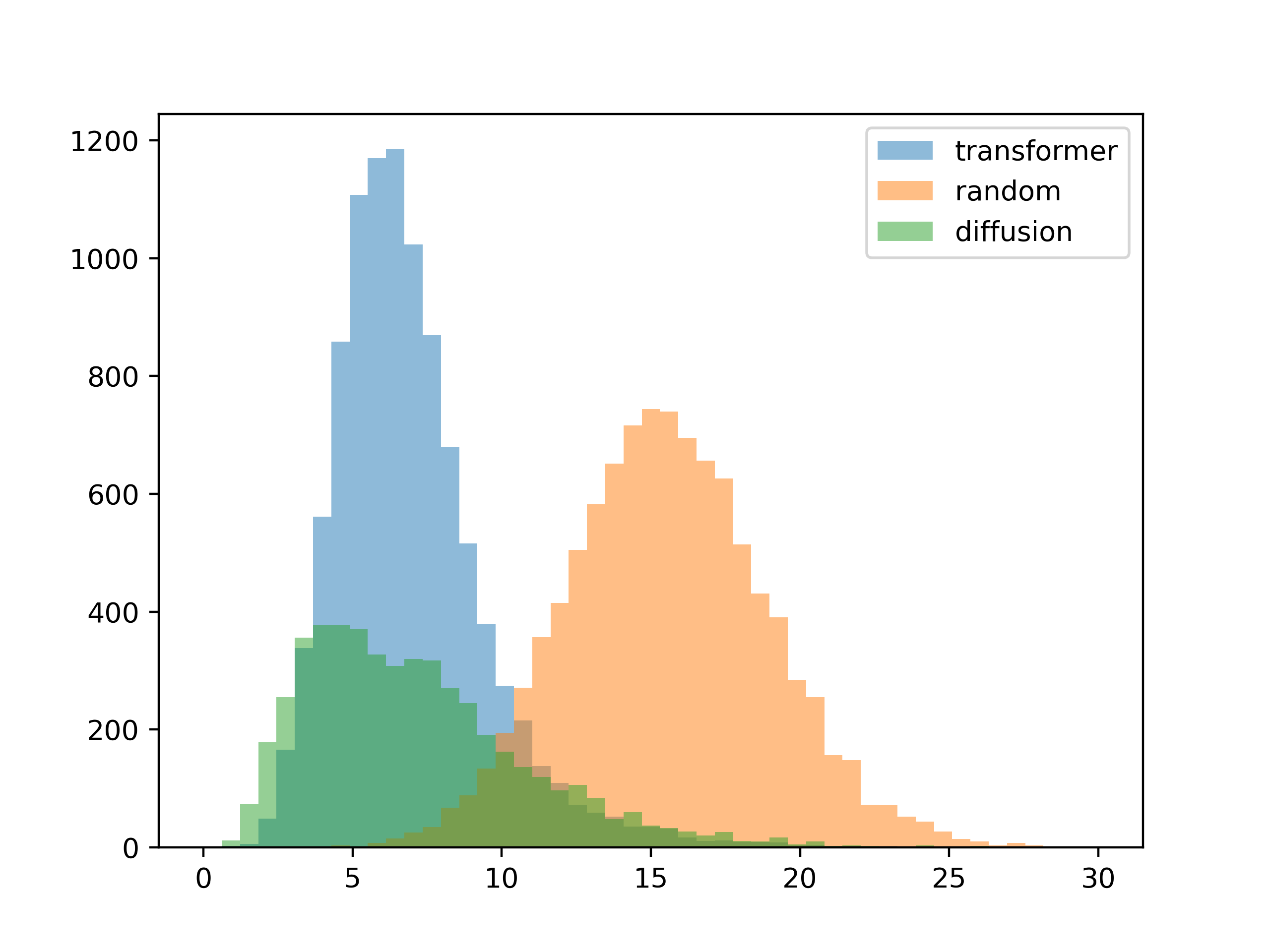 10种颜色
10种颜色对于这个测试,输入是训练集中的对比矩阵。 结果与预期差不多,扩散模型更符合输入对比度(您可以在梯度生成模板中直观地看到这一点)。
要查看系统的泛化能力,下一个测试是为其提供在训练期间未见过的输入。 为此,我随机创建了调色板,然后从这些随机颜色中提取了对比度矩阵。 然后使用这些有效随机的对比矩阵为第二个测试生成调色板。
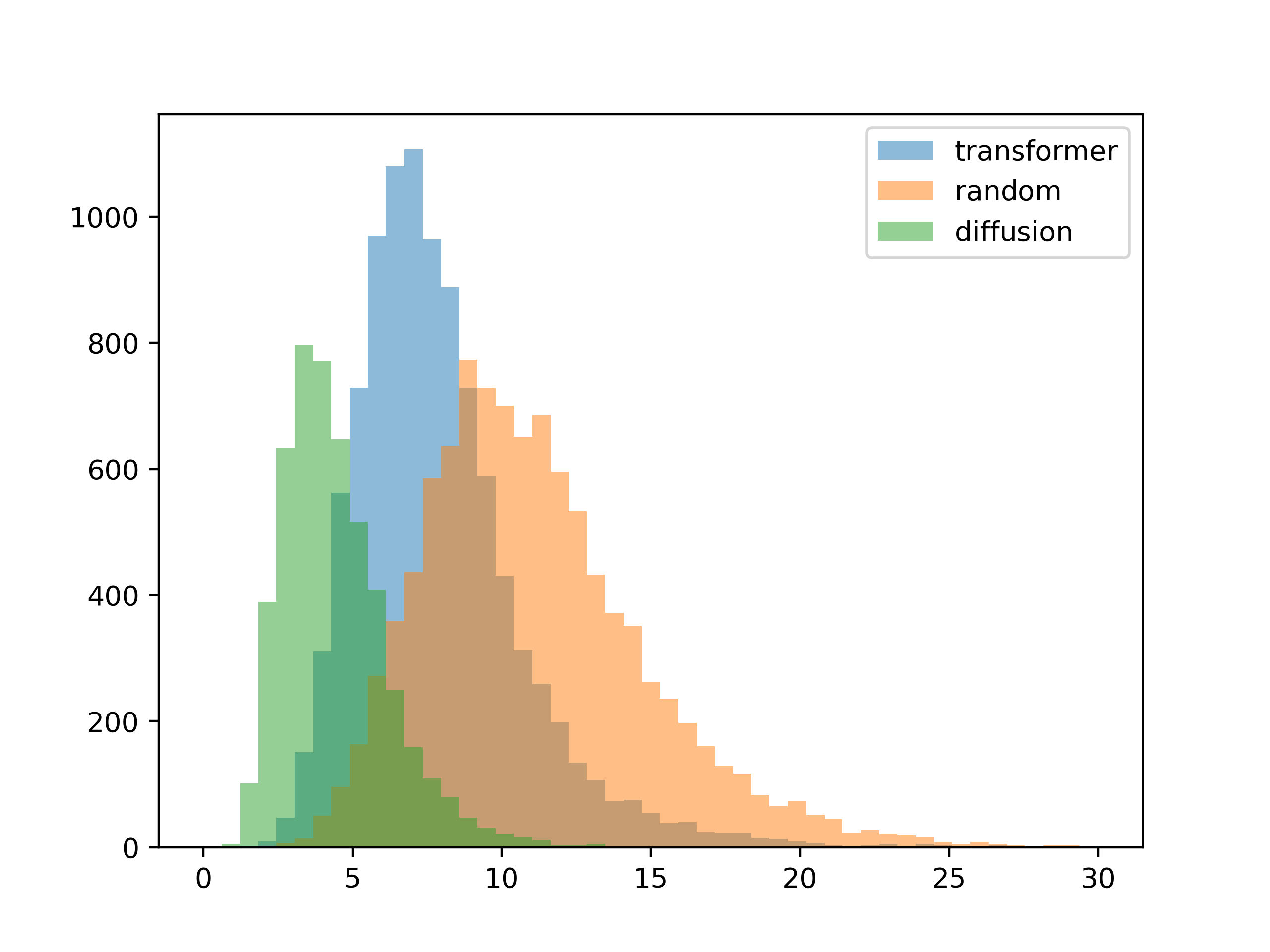 5种颜色
5种颜色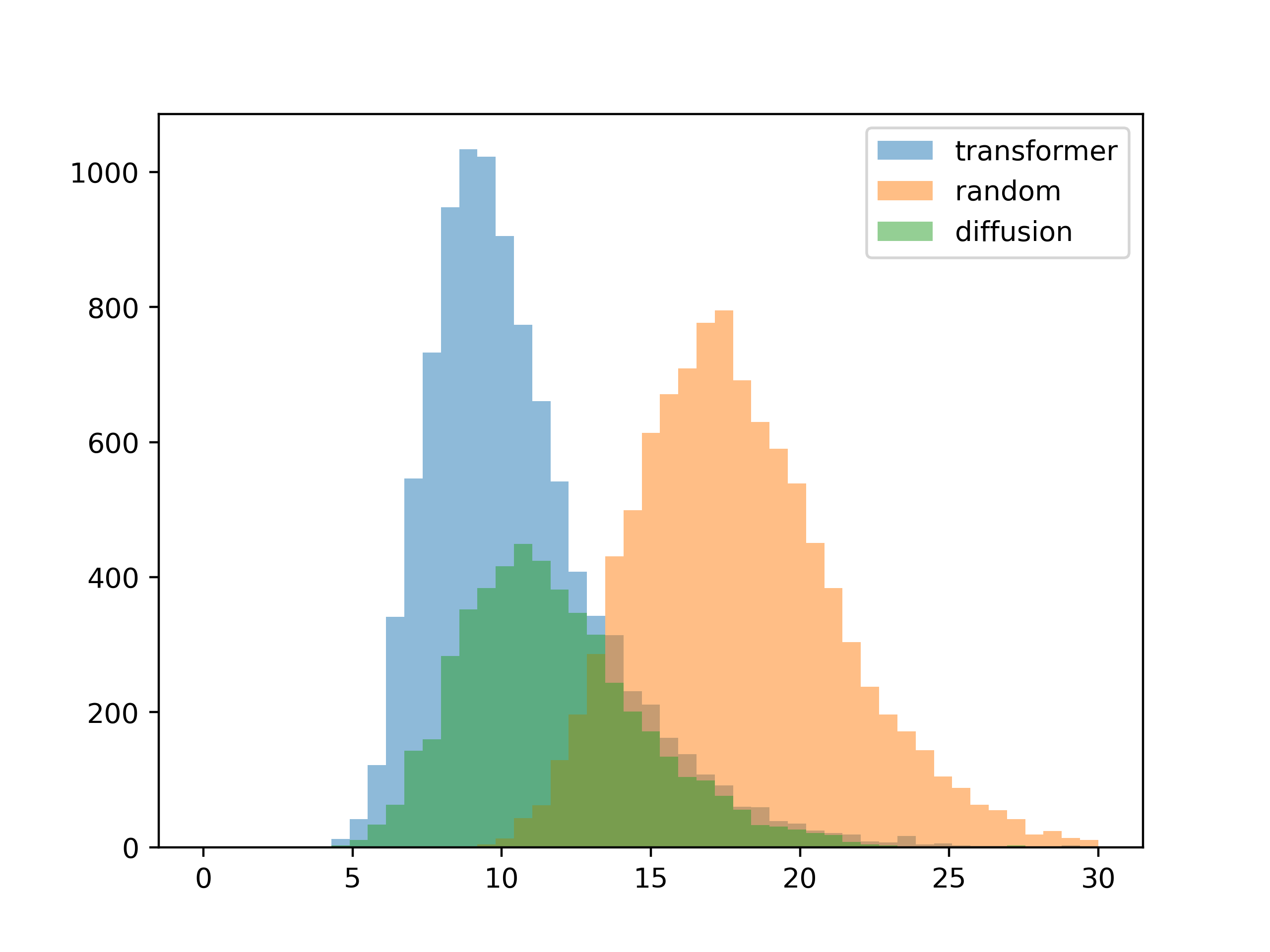 10种颜色
10种颜色绝对对比度值有点下滑,但这看起来很不错。
我想到的最后一个测试是当有一种或多种锁定颜色时系统的工作情况。
大多数世代看起来都很好,但扩散模型有一种奇怪的故障模式。
以下是失败案例的一些示例(第二种颜色锁定为白色,第三种颜色应为高对比度):

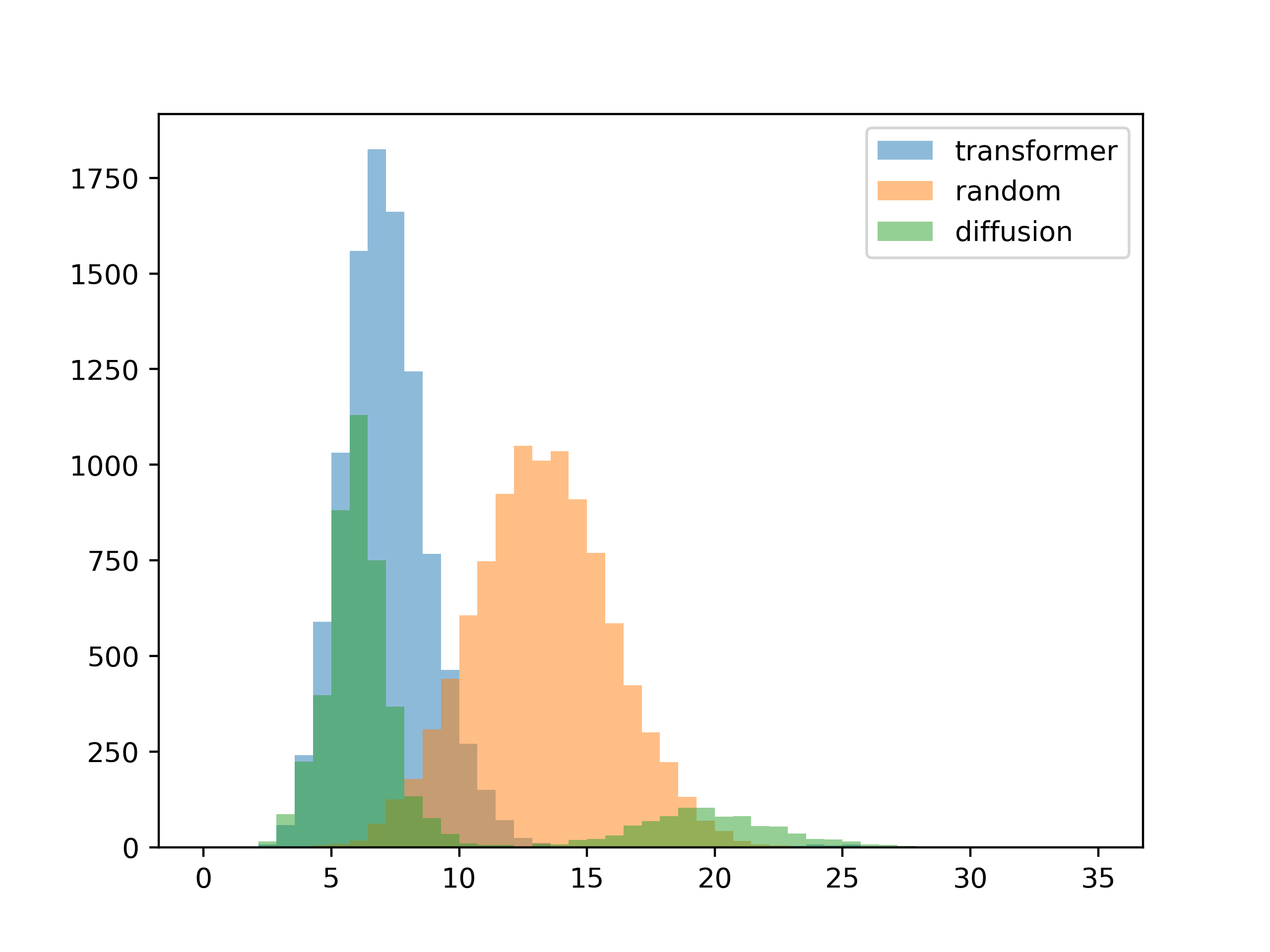
在检查了故障模式的采样过程之后,我很确定问题出在我实现锁定颜色的方式上。 在这一点上,我所做的就是在每个时间步用锁定的颜色覆盖模型的输出。 只要锁定的颜色接近“自然”生成,这就有效,但如果差异太大,它就会失败。 在这种特殊情况下,模型在每个时间步都试图使背景变暗并使前景变亮,而我手动将背景设置为白色并撤消其工作。
问题的根源是在训练期间看不到锁定的颜色,只能在运行时才实现。 我基本上回去并在 DDPM 模型中向 unet 添加了一个额外的输入,并从头开始重新训练它。 这允许模型在训练期间看到锁定的颜色并且似乎已经解决了问题。 这是在更新后的模型上重新运行的测试:
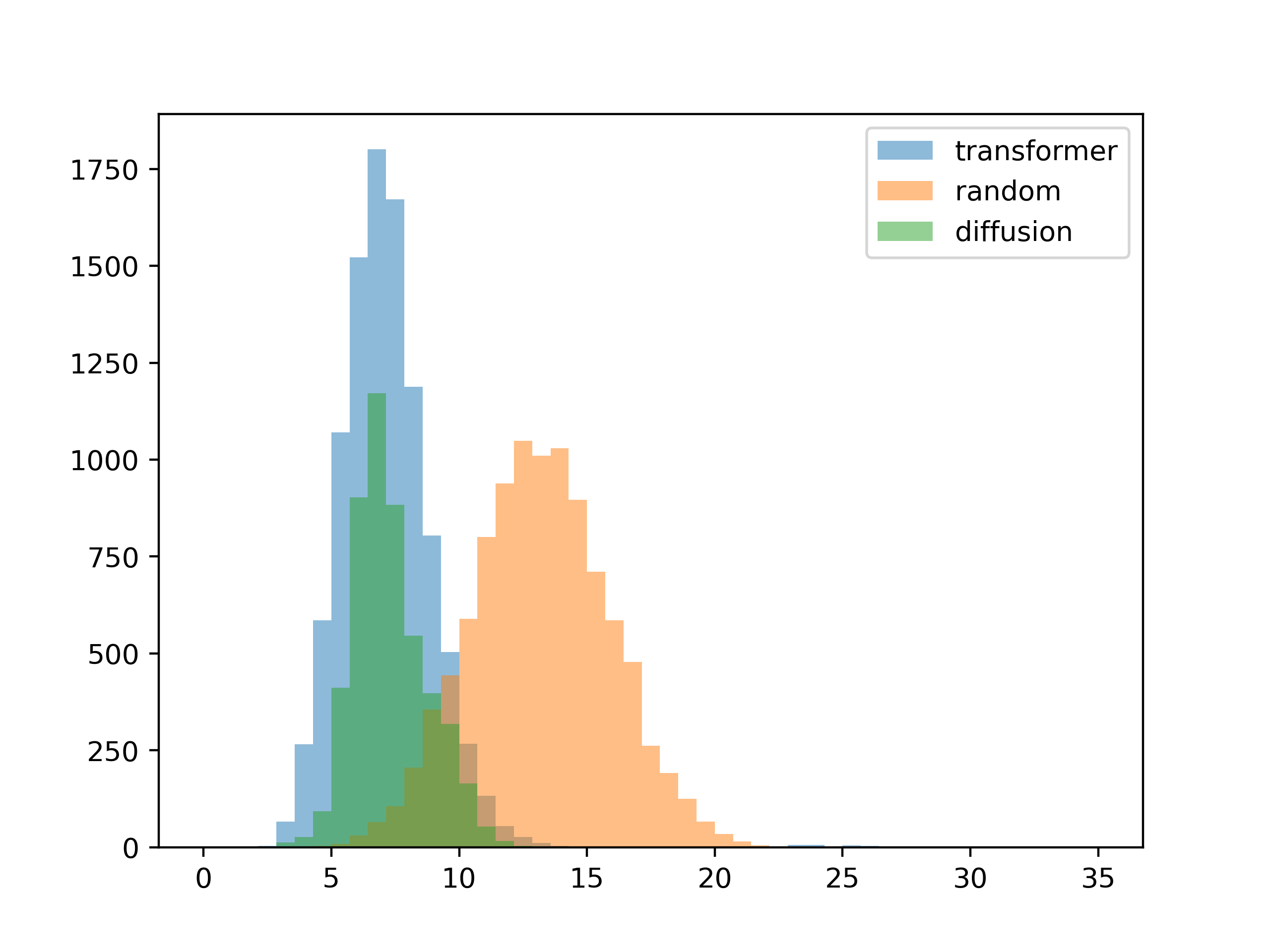
所以在这一切之后,我想回过头来指出这个系统的目标不是让这些直方图为 0。我们想要的是让系统提出新鲜的色彩设计理念,这是在结果与我们输入的结果完全一致的愿望不一致。 所以最终我们希望生成的调色板仅松散地遵循对比度输入,为过程添加噪音,以便发生某种偶然性。 对于变压器模型,可以通过增加采样温度方便地添加这种噪声,但我们如何使用扩散模型实现这一点?
我想出的答案是提前停止——通常 DDPM 模型需要 100-200 次迭代才能对图像进行完全去噪,但如果我们在全部去噪集通过之前停止,一些原始噪声仍然存在。 我设置了缩放比例,以便在温度 = 1.2(默认值)时没有提前停止,并且在最高温度下仅执行 70% 的去噪步骤(显然,最后的 30% 有很大的不同)。 这使得变压器和 DDPM 模型之间的行为在每个温度值上都有些相似。
未来的工作
将颜色生成视为条件图像生成任务是为图形设计创建颜色的一种极其有效的方法。 通过将图形设计抽象为颜色对比图,我们避免了处理密集像素值的需要,从而允许我们使用其他计算上难以处理的技术,如 DDPM。
然而,这种抽象删除了某些关键上下文,这可能有助于更精确的颜色生成。 例如,如果设计包含一个人,我们可能希望将输出限制为肤色,或者如果颜色用于警告消息,我们可能只需要红色阴影。 对于更多的上下文感知生成,添加额外的类标签可能是有益的。
固定的对比度值在某些情况下可能会受到限制 - 有时您可能需要最小对比度、最大对比度或一系列可能的值。 这将需要对要求进行更复杂的编码。
应用程序接口
随意将公共 API 用于非商业应用程序,但该服务“按原样”提供,无法保证正常运行时间。
// example"mode":"transformer" // transformer, diffusion or random
"num_colors":4, // max 12, min 2
"temperature":"1.2", // max 2.4, min 0
"num_results":50, // max 50 for transformer, 5 for diffusion
"adjacency":[ "0", "65", "45", "35", "65", "0", "35", "65", "45",
"35", "0", "35", "35", "65", "35", "0"], // nxn adjacency matrix as a
flat array of strings
"palette":["#ffffff", "-", "-", "-"], // locked colors as hex codes, or '-' if blank
}
type: "post",
url: "https://api.huemint.com/color",
data: JSON.stringify(json_data),
contentType: "application/json; charset=utf-8",
dataType: "json"
});
每个生成的调色板还带有一个分值,您可以使用该分值进行进一步过滤。 对于 transformer 模式,这个分数是生成的负对数似然(越接近 0 的可能性越大),对于随机模式,它是输入对比度差的平方和(越小越好)。 对于扩散模型,它是与输入对比度的最大绝对差异。
相关导航














